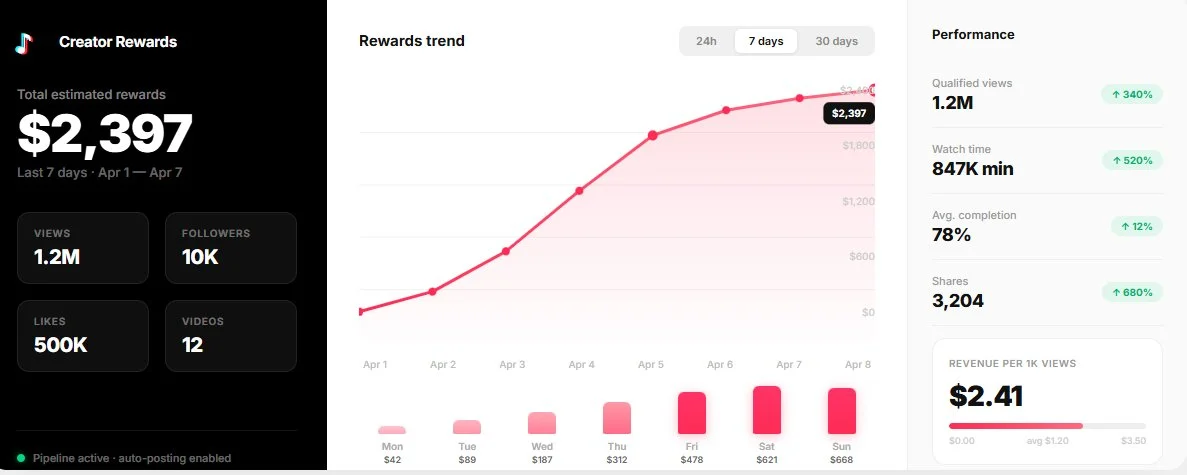
i built a research system for 4 clients in the past 6 months. one media company (well-known, can't name them), two consulting firms, and one independent analyst.
combined, they cut their research costs by about 60%. one of them fired 3 junior researchers and replaced them with this system + one senior editor who reviews the output.
no fancy tools. no $500/mo subscriptions. no 47 open chrome tabs.
just a folder of .md files, one ai agent (claude), and a system that takes one research question and produces a multi-angle analysis that would normally take a team 2 weeks.

this article is the full breakdown. every file, every link, every template. by the end you'll have a working research engine you can build in 1 hour.
what is a research skill graph?
most people use ai for research like this: open chatgpt, type "research X for me", get a surface-level summary that sounds like a wikipedia intro, then spend 3 hours verifying it and filling the gaps yourself.
that's not research. that's just a google search with extra steps.
the problem isn't the ai. it's that you're giving it zero structure. no methodology, no evaluation criteria, no framework for thinking about the topic from different angles. you're hiring a genius with amnesia every single time.
a research skill graph fixes this.
it's a folder of interconnected markdown files where each file is one "knowledge node", one piece of your research system's brain. inside each file you use [[wikilinks]] (double-bracket links like [[source-evaluation]] or [[contrarian]]) to reference other nodes.
when you point claude at this folder and give it a research question, it doesn't just google stuff. it follows the links, reads your methodology files, applies your source evaluation criteria, then analyzes the topic through 6 completely different lenses before synthesizing everything.
the difference: a single prompt gives you a summary. a skill graph gives you a research department.
why 6 lenses instead of one big prompt?
this is the core idea. instead of asking "research topic X", you force the ai to rethink the same question 6 times from fundamentally different angles:
- technical: what do the numbers actually say? look at data only
- economic: follow the money. who pays, who profits, what incentives drive behavior
- historical: what patterns repeat? what's been tried before? what context is everyone forgetting
- geopolitical: zoom out to the global chessboard. which countries, which power dynamics
- contrarian: what if the consensus is wrong? who benefits from the current narrative
- first principles: forget everything. rebuild from fundamental truths only
each lens produces findings that often contradict the others. and that tension between lenses is where the real insight lives.
when i ran "why are birth rates collapsing globally" through this system, the technical lens said "crisis: the math is brutal", while the contrarian lens said "japan has had low fertility for 50 years and hasn't collapsed." neither is wrong. the truth lives in the tension.
the folder structure you're going to build:
20 files. 6 folders. that's your entire research department.
go create this structure right now. open a folder on your desktop or in obsidian, make the subfolders, create empty .md files with those names. then come back and we'll fill every single one.
file 1: index.md (the command center)
this is the single most important file. every research starts here. it's not a table of contents, it's a briefing document that tells the ai who you are, what system you're using, and exactly how to execute.
notice: the node map gives context with every link. not just "[[technical]] — data" but "[[technical]], how does it work mechanically? what do the numbers actually say?" that extra context helps the agent make decisions without opening every file for every task.
file 2: research-frameworks.md (pick your approach)
file 3: source-evaluation.md (trust tiers)
this is what stops your research from being garbage-in-garbage-out. a 5-tier system for evaluating every source before using it.
file 4: synthesis-rules.md (combine without flattening)
this is the hardest part. most people skip synthesis and just stack facts. this file forces actual thinking.
file 5: contradiction-protocol.md (where the real insights hide)
most research buries contradictions. this system surfaces them on purpose. contradictions are features.
files 6-11: the 6 lenses
every lens file follows the same structure: core questions, how to research through that angle, output format, voice, and connections to other lenses. i'll show the technical lens as the detailed example, the other 5 follow the exact same pattern, you just swap the angle.
for the other 5 lenses, same structure but different core questions:
- economic: who pays, who profits, what incentives, what policies tried, what ROI?
- historical: when has this happened before, what conditions, what was tried, what worked?
- geopolitical: which countries most affected, what power shifts, what alliances change?
- contrarian: what's the mainstream narrative, what's the strongest argument against it, who benefits from the consensus?
- first principles: what are the absolute base-level facts, what's the simplest model that explains 80% of what we observe?
file 12: source-template.md
copy this for each major source you process during research.
the compound effect (why this gets better over time)
this is what makes the system fundamentally different from chatgpt conversations or google research.
knowledge/concepts.md and knowledge/data-points.md accumulate across ALL your research projects. after 5 projects, your ai starts with a base of 200+ verified data points and 50+ defined concepts.
research-log.md tracks every project with key findings and connections. your 10th project doesn't start from zero, it starts from everything you've already learned.
even better: the open-questions from one research become the index.md of the next. when i researched birth rates, one open question was "will ai automation offset labor shortages fast enough?", that's an entire research project that already has context from the demographic data.
and if you want a clean slate? just upload only methodology/ and lenses/ to a fresh claude project. no knowledge/, no research-log. same system, fresh brain.
how to use it
method 1: claude projects (recommended). create a new project, upload all files, give it a topic with "follow the execution instructions in index.md."

method 2: paste context. copy index.md + relevant lens files into any ai chat. less powerful but works anywhere.
method 3: claude code + obsidian (most powerful). point claude code at your local vault. the agent reads and writes files directly. the graph evolves itself, updating knowledge files, adding new concepts, refining lenses based on output quality. fully autonomous.
visualize with obsidian
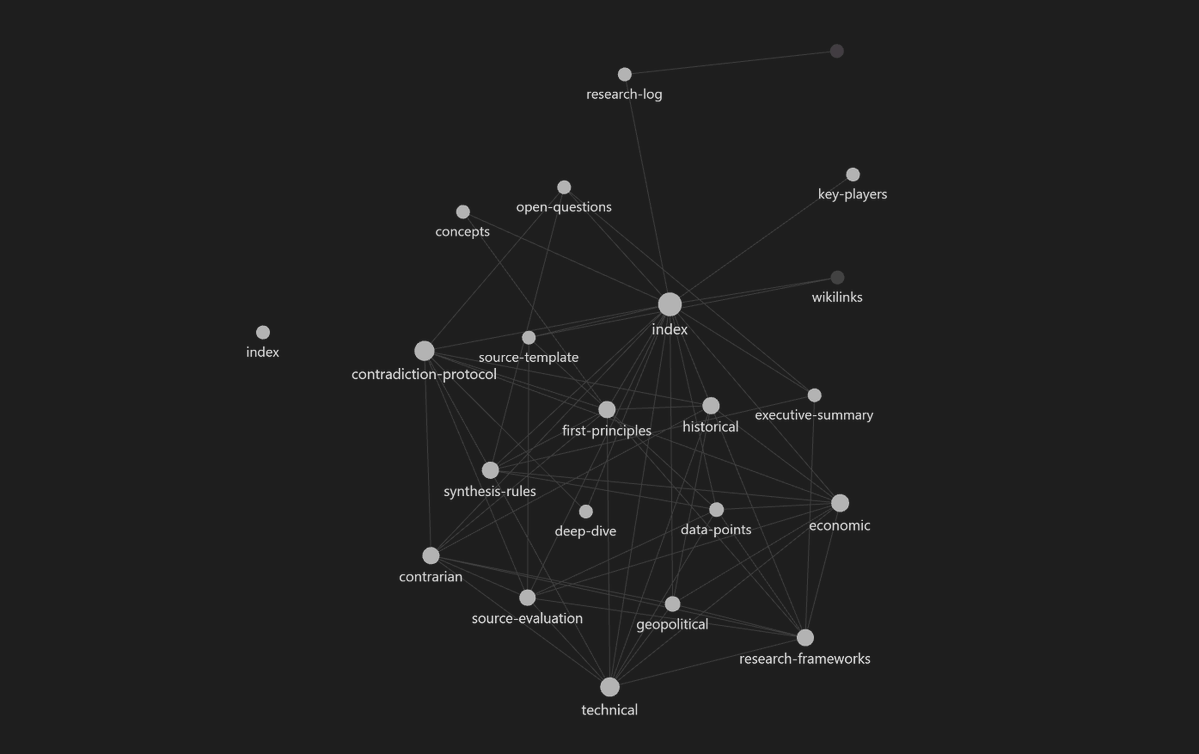
download obsidian (free) from obsidian.md. open your research-skill-graph folder as a vault. you immediately see a graph view showing how all your nodes connect.

index.md sits at the center. the 6 lenses radiate out. methodology files connect to lenses. knowledge files connect to everything.
two things this gives you: you can see which nodes are disconnected (research gaps) and spot unexpected connections between projects (compound insights).
obsidian is optional, the ai reads markdown regardless. but the visual graph makes the system tangible and helps you debug it.
why this beats traditional research
traditional research: open 50 tabs, read 20 articles that all say the same thing, miss the contrarian view, miss the historical pattern, get lost in confirmation bias, produce a summary that sounds smart but has no structure.
skill graph research: one question goes through 6 forced angles, each angle has evaluation criteria, contradictions are documented not hidden, sources are tiered, findings compound across projects.
the biggest difference is the contrarian lens. traditional research almost never challenges its own findings. this system has a built-in devil's advocate that asks "what if everything i just found is wrong?", and rates the strength of the counter-argument honestly.
build it in 1 hour:
- create the folder structure. 20 files, 6 folders. takes 5 minutes
- fill index.md first: this defines everything else
- fill the 6 lens files with the core questions and output formats
- fill methodology/ with source evaluation tiers and synthesis rules
- upload everything to a claude project
- give it a topic and test
- iterate. update the lens files based on output quality. add concepts to knowledge/ after each project
the system gets better every time you use it. that's the whole point.