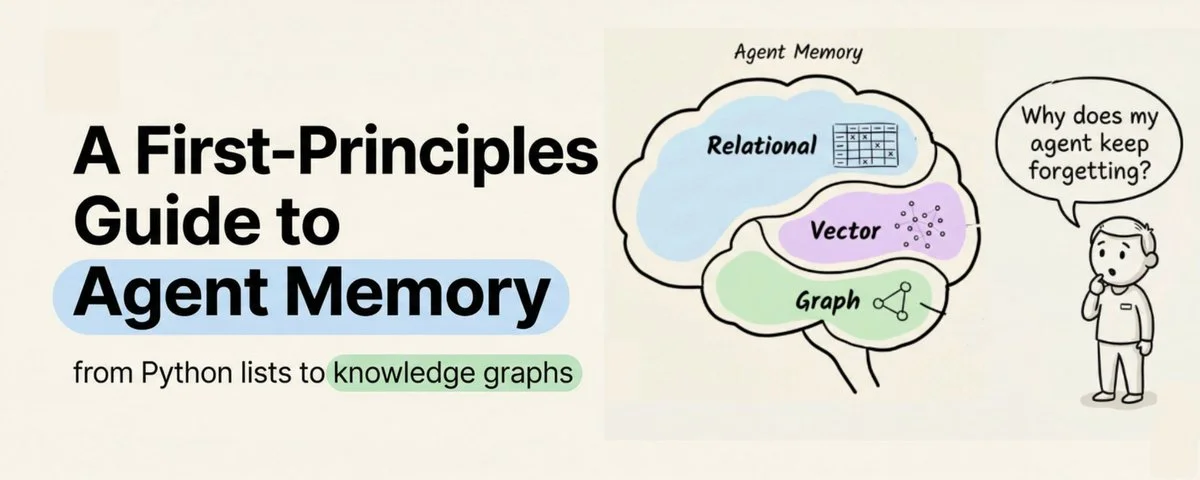
A first-principles walk through agent memory: from Python lists to markdown files to vector search to graph-vector hybrids, and finally, a clean, open-source solution for all of this.

An LLM is stateless by design. Every API call starts fresh. The "memory" you feel when chatting with ChatGPT is an illusion created by re-sending the entire conversation history with every request.
That trick works for casual chat. It falls apart the moment you try to build a real agent.
Here are 7 failure modes show up the instant you skip memory:
- Context amnesia: the agent asks for information you already gave it
- Zero personalization: every interaction feels generic
- Multi-step task failure: intermediate state silently drops mid-task
- Repeated mistakes: no episodic recall means the same errors, forever
- No knowledge accumulation: every session starts from scratch
- Hallucination from gaps: when context overflows, the model invents
- Identity collapse: no continuity, no trust
The obvious response is "throw more context at it." That's why 128K and 200K token windows feel like they should solve everything.
They don't.
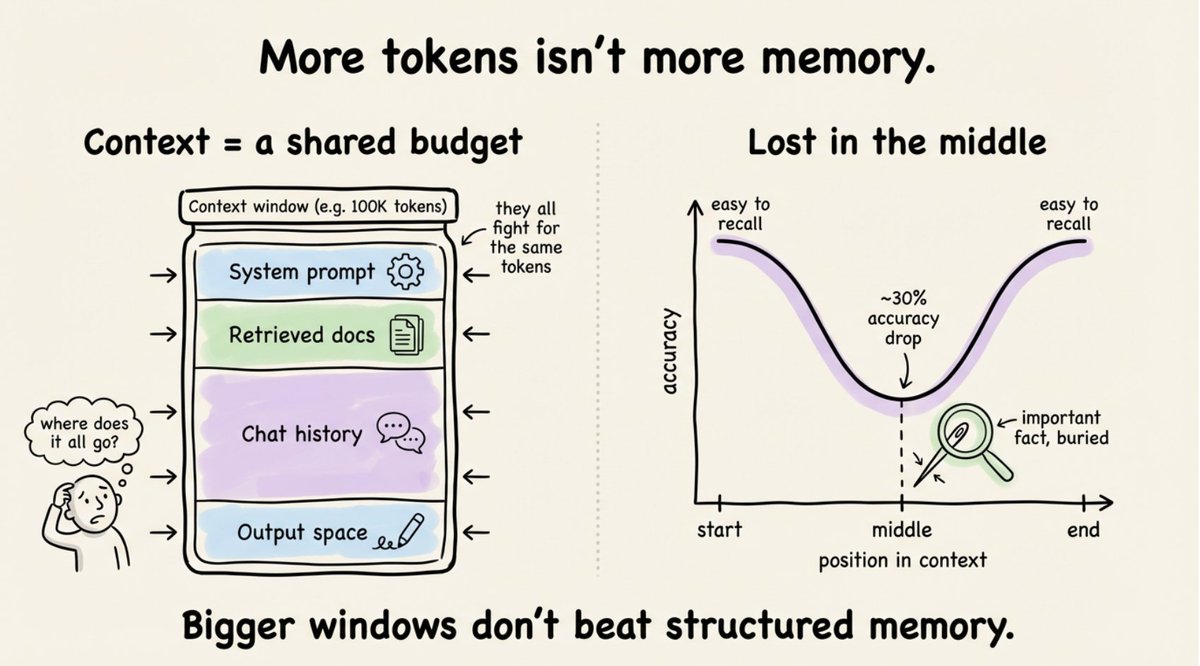
Accuracy drops over 30% when relevant information sits in the middle of a long context. This is the well-documented "lost in the middle" effect.
Context is a shared budget: system prompts, retrieved docs, conversation history, and output all fight for the same tokens.
Even at 100K tokens, the absence of persistence, prioritization, and salience makes raw context length insufficient.
Memory isn't about cramming more text into the prompt. It's about structuring what the agent remembers so it can find what matters.
The cognitive science frame that actually helps
Lilian Weng's 2023 formulation has become the default framework:
Agent = LLM + Memory + Planning + Tool Use.
The four co-equal pillars.
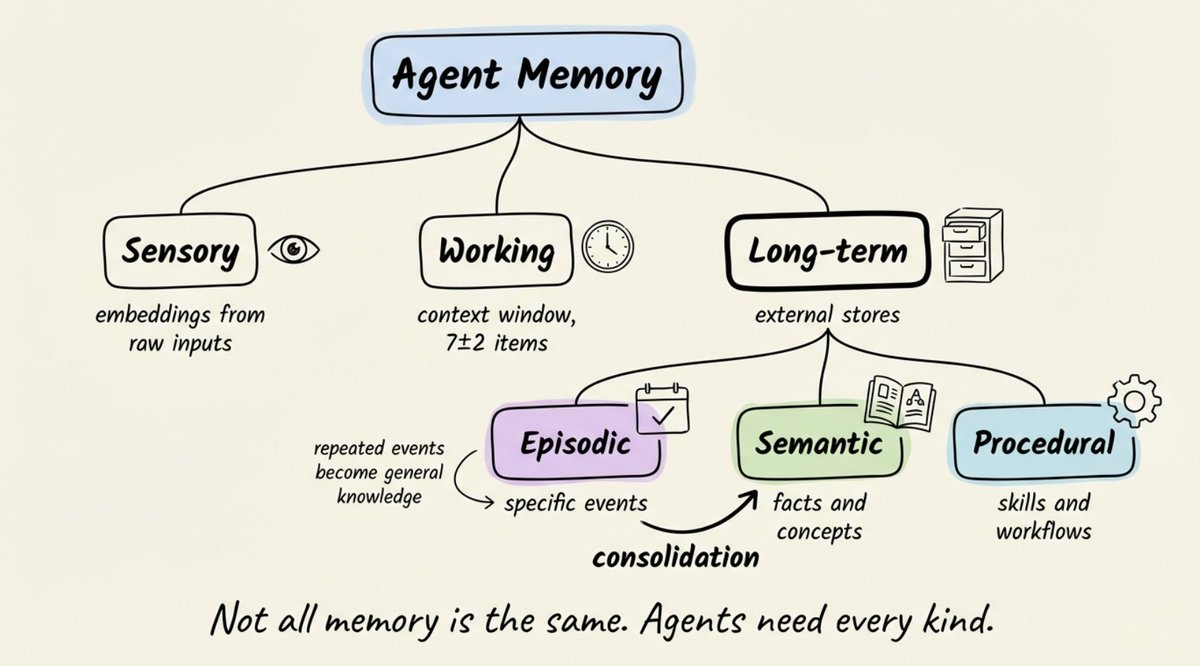
Her taxonomy borrows from cognitive science, where human memory splits into three systems:
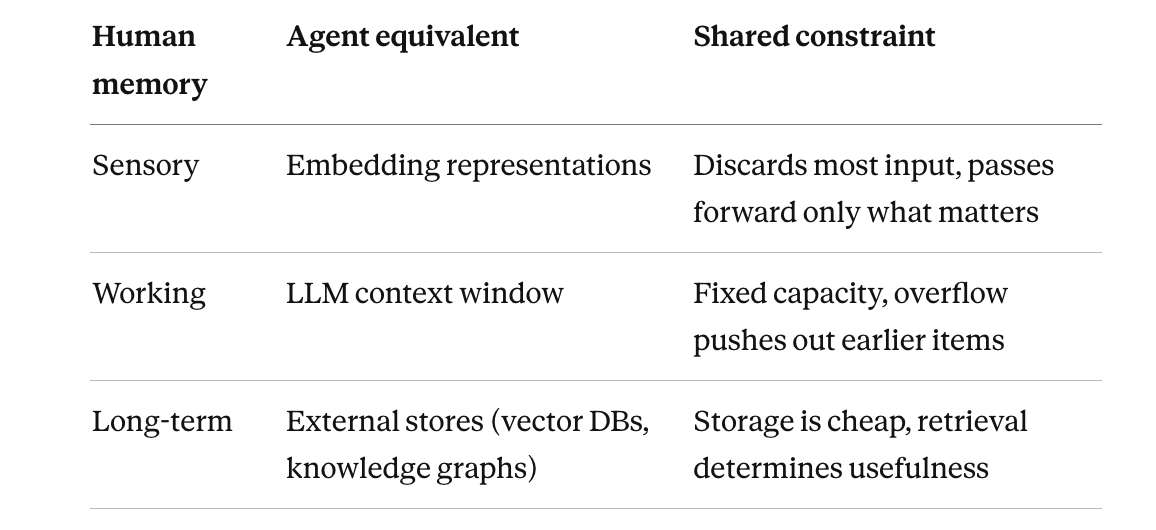
- Sensory memory captures raw perceptual input and holds it for a fraction of a second. Only the portions you pay attention to get passed forward.
- Working memory is where active thinking happens. It holds roughly 7±2 items at a time (Miller's 1956 finding). Lose focus, and the contents disappear.
- Long-term memory is durable storage with no practical capacity limit. Retrieval is the bottleneck: you can store millions of things and still fail to recall the one you need.
Each maps directly to a component in modern agent architectures:
Long-term memory itself splits further:
- Episodic: specific past events ("on Tuesday, the PostgreSQL cluster went down")
- Semantic: facts and concepts ("PostgreSQL is a relational database")
- Procedural: skills and workflows ("when a user asks for a refund, first check the purchase date")
The bridge between episodic and semantic is memory consolidation: repeated specific events distilling into general knowledge. An agent that notices "users consistently prefer executive summaries" across dozens of interactions should turn that into a reusable rule. Without consolidation, your agent replays individual events rather than learning from them.
The minimal agent, and what breaks first
Strip away the frameworks and an agent is a loop: perceive, think, act.
Tell it "I have 4 apples," then ask "I ate one, how many left?" and it has no idea what apples you're talking about. Each call exists in isolation.
Layer 1: The Python list
The first fix everyone reaches for:
Multi-turn works now. The apples question gets answered correctly because the full conversation re-ships with every call.
Two problems show up fast:
- The list grows unbounded. Around turn 200, you hit the context ceiling and the oldest messages silently drop. The user's name from turn 1 disappears long before yesterday's throwaway joke. No prioritization, just strict chronological order.
- Everything lives in RAM. The moment the Python process ends, your agent has no idea who you are.
Layer 2: Markdown files for persistence
The next move is writing memory to disk. Markdown is a natural fit: human-readable, Git-friendly, and the agent can read it back as plain text. Claude Code uses exactly this pattern with CLAUDE.md and MEMORY.md files.
Persistence is solved. Restart the script, and the conversation is still on disk. You could also maintain a separate facts file that the agent extracts over time:
You can open the file in any editor, see exactly what the agent knows, and fix it by hand. Genuinely useful for prototyping.
With 4 facts, this works perfectly. Load the entire file into context and the LLM handles any question about Sarah, her company, or her industry.
Now fast-forward three months. Your agent has 2,000 extracted facts and 200 conversation logs. That's 500K+ tokens of markdown on disk, and your context window is 128K.
You can no longer load everything. You need to selectively retrieve only the facts relevant to the current query. With flat files, your only option is keyword search:
At small scale, markdown files work. At real scale, they force keyword retrieval, and keywords can't handle synonyms, paraphrases, or connections across facts.
The information is on disk. But you can't load all of it, and keyword search is too brittle to find the right pieces.
If you've used OpenClaw, you've seen this play out. It stores memory as markdown checkpoint files, and over weeks of daily use, earlier facts quietly slip away as context accumulates and gets compacted. The storage is there. The retrieval isn't.
Storage without intelligent retrieval is a library with no catalog.
Layer 3: Vector search and the wall it hits
Bolt on embeddings. Chunk your markdown, embed the chunks, search by cosine similarity. Now "database" matches "PostgreSQL" because their vectors live close together in embedding space. The synonym problem dissolves.
Then you hit a new wall. Consider these three facts in your vector DB:
User asks: "Was Alice's project affected by Tuesday's outage?"
The query mentions Alice and Tuesday's outage, so vector search ranks the first and third facts high. But the critical bridge, "Project Atlas uses PostgreSQL," mentions neither Alice nor Tuesday. It's the connecting piece, and it's the one that won't surface.
Each fact is an isolated point in embedding space. The connective tissue linking them is invisible to vectors.

This isn't an edge case. It's the normal shape of real-world questions. Business knowledge is inherently relational: people belong to teams, teams own projects, projects depend on systems, systems have incidents. Any question that crosses two or more hops exceeds what flat vector retrieval can answer.
The capability matrix
Each layer fixes the previous pain but reveals a deeper one:
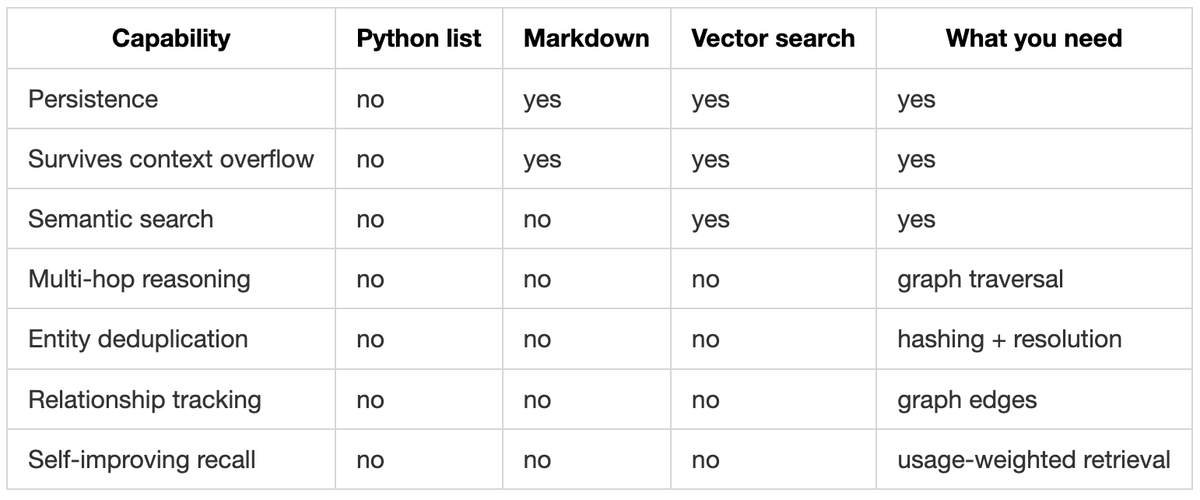
You need persistence, semantic understanding, and relational reasoning in a single memory layer.
Building this yourself means gluing together a vector database, a graph database, a relational store, an entity extractor, a deduplication pipeline, and an edge-weighting system. That's weeks of infrastructure work before you write a single line of agent logic.
I've been using a solution that fills this gap cleanly. It's fully open-source, handles all three storage paradigms under one roof, and you can get it running in minutes. Let's talk about Cognee.
Cognee: three stores, one engine, four calls
Cognee is an open-source knowledge engine built for agent memory. It combines vector search with knowledge graphs and a relational provenance layer into a single system.
The entire API surface is four async calls:
Behind those four calls sits a three-store architecture.
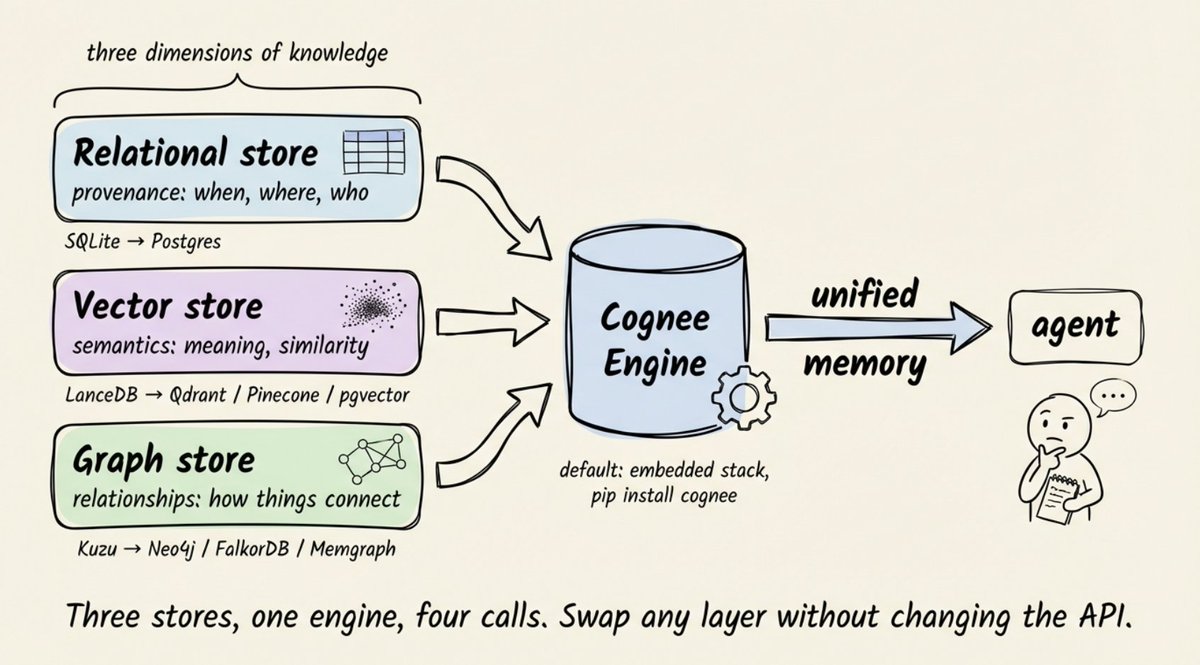
Why three stores and not one ?
Each store captures a dimension of knowledge the others can't:
- Relational store → provenance: where data came from, when it was ingested, who has access
- Vector store → semantics: what content means, what it's similar to
- Graph store → relationships: how entities connect, what causes what, who reports to whom
Flatten any of these and you lose information that matters for retrieval accuracy.
The default stack is SQLite + LanceDB + Kuzu, entirely embedded and file-based. pip install cognee plus an LLM API key and you're running.
No Docker, no external services.
For production, swap SQLite for Postgres, LanceDB for Qdrant/Pinecone/pgvector, and Kuzu for Neo4j/FalkorDB/Neptune.
Same four-call API either way.
What cognify actually does?
cognee.cognify() runs a multi-stage pipeline that converts raw text into structured, interconnected knowledge:
- Document classification by type and domain
- Permission checking for multi-tenant access control
- Chunk extraction that respects paragraph structure (not fixed-size cuts)
- Entity and relationship extraction via LLM, with automatic deduplication through content hashing
- Summary generation for efficient retrieval
- Dual indexing into the vector store (embeddings) and graph store (edges)
The deduplication step matters more than it sounds. If the same entity shows up across 50 documents, Cognee merges it into a single graph node with 50 inbound edges. Your agent no longer sees "Alice" as 50 different strangers. And the pipeline is incremental by default: only new or updated files get reprocessed.

Every graph node has a corresponding embedding. This dual representation is the core trick: enter through vectors (find semantically similar content) and exit through the graph (follow relationships to connected entities), or the reverse. That's what makes multi-hop queries work without sacrificing semantic search.
Memify: memory that learns
memify() is what separates Cognee from every "ingest and search" tool. It runs an RL-inspired optimization pass over the graph:
- Strengthening useful paths that led to good retrieval
- Pruning stale nodes that haven't been touched
- Auto-tuning edge weights based on real usage
- Adding derived facts by identifying implicit relationships
A customer support agent's graph naturally strengthens paths through product docs and refund policies while letting rarely-queried HR edges decay. The graph develops its own sense of relevance over time.

Fourteen retrieval modes
Cognee ships 14 search modes. The ones you'll actually reach for:

Building a real agent with Cognee memory
Here's the complete pattern wiring Cognee into the perceive-think-act loop:
The memory cycle: ingest, extract, store, retrieve, respond, store again. Each turn enriches the knowledge graph, and incremental processing means you only pay to index new content.
Session memory handles pronoun resolution automatically:
Multi-tenancy is built in at the graph level with per-dataset permissions (read, write, delete, share). Not namespace separation, actual graph-level isolation.
The practical path forward
If you're building an agent today, the real starting question is: "what does my agent need to remember, and what kind of questions will it answer?"
If your queries only need similarity search ("find conversations like this one"), vector-only memory works. The moment queries cross entity boundaries ("Was Alice's project affected by Tuesday's outage?"), you need graph traversal.
You can wire together separate vector, graph, and relational stores yourself. Teams that go this route typically burn weeks on infrastructure for a memory layer that still doesn't learn from its own usage.
Cognee collapses that into four API calls. Embedded defaults get you running in minutes. Swappable backends (Postgres, Qdrant, Neo4j) take you to production without changing your agent code.
Intelligence requires structure, not just storage. The three storage paradigms (relational, vector, graph) aren't competing options. They're complementary layers of the same memory system. Treating them that way is what turns a stateless LLM wrapper into something that actually learns.
What's the next thing you'd want your agent to remember tomorrow that it forgot today? Start there.
👉Check out Cognee on GitHub →, give it a star, and try wiring it into your next agent.
Four async calls, a pip install, and you're running.
That's a wrap!
If you enjoyed reading this:
Find me →@akshay_pachaar ✔️
Every day, I share tutorials and insights on AI, Machine Learning, and vibe coding best practices.